Hypothetical Implementation of Field-Programmable Gate Arrays in Discreet Low-Profile Real-Time Image Analysis and Classification
Hypothetical Implementation of Field-Programmable Gate Arrays in Discreet Low-profile Real-time Image Analysis and Classification
Daniel P Corcoran
University of Cincinnati College of Engineering and Applied Science
Abstract: State-of-the-art implementations of real-time object detection systems remain limited by many factors. The neural networks at the core of systems such as YOLOv3 [1] are not capable of real-time object detection without a dedicated video card or substantially powerful CPU. The prospect of implementing a low-profile real-time neural image classification system has until now remained unheard of. Through proper implementation of a Field-Programmable Gate Array, a Raspberry Pi Zero W would hypothetically be capable of achieving desktop-speed image analysis (10-30FPS) [2] while maintaining a low physical footprint and low power profile. With this implementation a network of self-contained "Neural Cameras" could independently parameterize and report data to a thin client or web client with no dependence on external processing.
Introduction:
Problem Analysis: Current implementations of neural networks require expensive
Motivation: I believe that by parameterizing and analyzing visual data independently from typical neural network systems that the computational challenges of cognitive awareness and situational awareness can be separated. By simplifying the process of collecting and analyzing visual data, exciting new applications can be developed across many industries.
Potential Applications:
1. Streamline employee evaluations by directly quantifying performance metrics
2. Enhance classroom engagement by directly quantifying individual student attention
3. Augment wildlife research by autonomously collecting, categorizing, quantifying and parameterize biology data across a wide area
4. Identify which items need to be restocked or reorganized
5. Identify which areas need to be cleaned
6. Automatically clock in/clock out employees
7. Automatically evaluate quality of complex products
8. Simplify deployment of intelligent robots
9. Simplify geographical surveying
10. Quantify and analyze behaviors, shopping habits, tastes and preferences of large aggregate groups
System Design Overview:
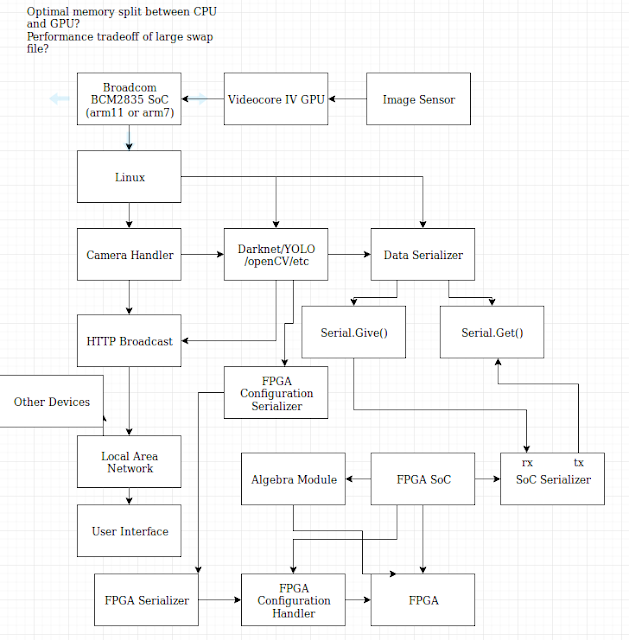
Included is a rudimentary overview of the fundamental elements of the system.
Not an FPGA, but the intel movidius basically does exactly what I want, minus the camera.
Problem Analysis: Current implementations of neural networks require expensive
Motivation: I believe that by parameterizing and analyzing visual data independently from typical neural network systems that the computational challenges of cognitive awareness and situational awareness can be separated. By simplifying the process of collecting and analyzing visual data, exciting new applications can be developed across many industries.
Potential Applications:
1. Streamline employee evaluations by directly quantifying performance metrics
2. Enhance classroom engagement by directly quantifying individual student attention
3. Augment wildlife research by autonomously collecting, categorizing, quantifying and parameterize biology data across a wide area
4. Identify which items need to be restocked or reorganized
5. Identify which areas need to be cleaned
6. Automatically clock in/clock out employees
7. Automatically evaluate quality of complex products
8. Simplify deployment of intelligent robots
9. Simplify geographical surveying
10. Quantify and analyze behaviors, shopping habits, tastes and preferences of large aggregate groups
System Design Overview:
Included is a rudimentary overview of the fundamental elements of the system.

TODO: Include representation of memory management between FPGA and
Pi.
IMPORTANT: Look into openVINO (Accleration library for optimized computing with inte's hardware portfolio)
FPGA Design:
Simple FPGAs that are in my budget:
Not an FPGA, but the intel movidius basically does exactly what I want, minus the camera.
Useful Exerpt from [4]:
_______________
One approach to reduce the silicon count (therefore
power consumption) required for machine learning inference is
reducing the dynamic range of calculations [4]. Reducing from 32-bit
to 16-bit floating point arithmetic, for example, only slightly
reduces the application performance in recognition accuracy, yet can
greatly reduce hardware requirements.
...
Processing convolutions within CNN networks require
many millions of coefficients to be stored and processed.
Traditionally, each of these coefficients are stored in full single
precision representation. Research has demonstrated that coefficients
can be reduced to half precision without any significant change to
overall accuracy hile reducing the amount of storage needed and
memory bandwidth requirements. Most of the pre-trained CNN models
available today use partially reduced precison.
_____________
TODO:
1. Calculate the resources required to perform 1024
16 bit accumulations that represent each 32x32 convolution
2. Develop serial pathway for memory management
between FPGA and
Data Serialization:
-Develop general format for forwarding matrix data to FPGA controller
-Develop general format for forwarding matrix data to FPGA controller
Neural Network Library Compatibility:
-Implement data serialization service in place of the CUDA service in darknet... Is darknet the best choice for NN library? (Assuming so considering most general software compatibility issues have been worked out on pi)
-Implement data serialization service in place of the CUDA service in darknet... Is darknet the best choice for NN library? (Assuming so considering most general software compatibility issues have been worked out on pi)
Results:
Anecdotal - Running TINY-YOLO weights on Pi zero W SoC (64Mb to GPU, 1gb swap file, 850mHz clock, 2.4A power and serial-USB connection to windows while running SSH still takes 2 minutes to process a frame).
-I'd like to do some preliminary testing with an intel mobidius, worth shelling out $$$ for?
Anecdotal - Running TINY-YOLO weights on Pi zero W SoC (64Mb to GPU, 1gb swap file, 850mHz clock, 2.4A power and serial-USB connection to windows while running SSH still takes 2 minutes to process a frame).
-I'd like to do some preliminary testing with an intel mobidius, worth shelling out $$$ for?
Assumption:
-Will the size of the FPGA be enough to handle most neural network applications? Am I being too
Future Improvements:
Conclusion:
-Will the size of the FPGA be enough to handle most neural network applications? Am I being too
Future Improvements:
Conclusion:
Acknowledgements:
Citations:
[1]
https://pjreddie.com/media/files/papers/YOLOv3.pdf
[2] https://www.youtube.com/watch?v=_iMboyu8iWc
[3]
https://forums.xilinx.com/t5/Xcell-Daily-Blog-Archived/Tincy-YOLO-a-real-time-low-latency-low-power-object-detection/ba-p/815840
[4] https://www.bittware.com/resources/bwnn/
[5]
https://www.researchgate.net/publication/323375650_A_Lightweight_YOLOv2_A_Binarized_CNN_with_A_Parallel_Support_Vector_Regression_for_an_FPGA


Comments
Post a Comment